For smart driving applications, how should deep learning be implemented?
In this article, forward Qi Chuang & CTO Zhang Hui introduced some experience of forward Qi Chuang on the TI TDA chip, using deep learning methods to solve the problem of intelligent driving perception.
With its powerful feature representation capabilities, deep learning has already demonstrated excellent performance in many application fields. For smart driving applications, how should deep learning be implemented?
Forward Qichuang & CTO Zhang Hui believes that there are two major technical challenges: one is the selection of the main chip, and the other is the design and implementation of deep learning algorithms for specific chips.
Qian Xiang Qi Chuang & CTO Zhang Hui, graduated from Huazhong University of Science and Technology in 2004 with a double bachelor's degree; worked in Ankai Microelectronics in the United States from 2004 to 2005 as an algorithm engineer; worked in ZORAN (CSR/Qualcomm) in the United States from 005 to 2013 The company, as the manager of algorithm research and development; nearly 15 years of experience in algorithm chip and productization; published many academic papers at ACCV, ICPR and other international conferences; holds a number of Chinese and American invention patents.
TI smart driving ASIC
For the selection of the main processor chip of the intelligent driving product, the main requirements of the intelligent driving product-high reliability and low cost should be used as the main reference basis.
From the perspective of the industry, the main chips for smart driving can be divided into two major schools. One is ASIC, which converts specific algorithm calculation engines into chips, representing companies such as TI, Mobileye, nVidia, Ambarella, etc.; the other is FPGA, representing companies like Xilinx, Altera, etc.
With its customization, ASIC has achieved a better balance in cost, power consumption, computing power, flexibility, vehicle specifications, functional safety level, and mass production cycle.
TI (Texas Instuments) began to provide the TDA (TIDriverAssist) series of ASIC chips for intelligent driving since 2010, and it has been iterated to the fourth generation.
After years of evolution, TI has gradually turned a number of algorithms for intelligent driving into chips and engines, and its functional safety level has also reached ASIL-C.
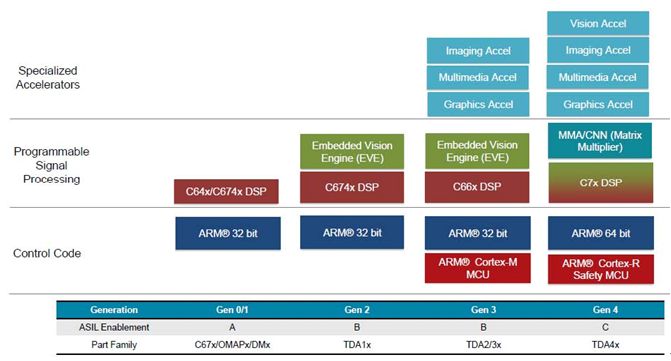
TI's ASIC chip TDA (TIDriverAssist) series
TI's smart driving chips have been adopted by more than 15 Tier1 and 25 OEM OEMs around the world due to their excellent price/performance ratio. They have been successfully mass-produced in nearly 100 models and have shipped nearly 40 million pieces. At present, Forward Qichuang also uses TI ASIC chips.
Deep network design
Network model design is the key to deep learning applications. How to design an intelligent driving perception network that can meet product requirements?
Zhang Hui believes that there are two key points. First, it needs to be close to the task and system requirements, that is, the network design must be based on the demand for the perception layer of the intelligent driving system application, and the deep neural network must not be selected for the use of deep learning;
Second, it is necessary to take into account that the computing power of the chip embedded platform is limited. The core design must not blindly stack the network, resulting in excessive calculations and the problem of being unable to deploy on the chip.
From the perspective of intelligent driving tasks, the Level2–Level3 system puts forward higher requirements for perception. For example, AEB-Cross needs to detect the side state of the vehicle, and TJA (TrafficJamAssistance) needs to identify the passable area, namely FreeSpace, and so on.
For vehicle side detection, Qianxiang Qichuang redesigned a FINet network, extending the traditional 2D-BoundingBox to 3D-BoundingBox, which can detect multiple surfaces of the vehicle.

Forward Qichuang's FINet network designed for vehicle side detection
For the FreeSpace mission, FINet redesigned by Forward Qichuang can decompose this mission into three categories: Flat and passable areas; Step along the road; and Obstacle obstacles.

For FreeSpace missions, FINet is broken down into three categories of targets
Deep network optimization
Common deep learning networks have relatively high requirements for the computing power of the main chip.
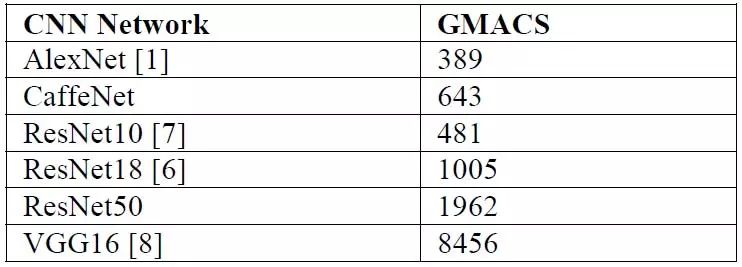
Common network requirements for computing power when inferring 720P@30fps images
As can be seen from the above figure, most networks require more computing power than 1Tops, and low-power chips like TITDA2x currently cannot meet the computing power requirement of 1Tops. Therefore, after the basic network model is designed, in order to greatly reduce the GMACS of the model to adapt to the chip platform with limited computing power, it is necessary to fine-tune the network (FineTuning) and optimize the chip.
For TIASIC's chip architecture, Forward Qichuang mainly uses two major methods to optimize the network, the first is convolution sparseness, and the second is 8-BIT quantization technology.
First, the convolution sparsity method is to adjust the loss function to zero the coefficients in the convolution kernel whose weight is less than the dynamic threshold, and then re-tune the sparsity tensor to zero the coefficients. The latter coefficients are no longer back-propagated and updated, and finally, the training accuracy is not significantly reduced under the condition of ensuring the sparsity.

Under two objective functions with different sparsity, the kernel of the filter trained by tuning
Second, dynamic 8-BIT quantization technology. Dynamic refers to improving the quantization accuracy of a tensor as high as possible under the premise of the maximum bit width of 8-BIT. The range of the volume is adjusted dynamically.
After completing the above two steps of optimization, the FINet network of Forward Qichuang has been accelerated by nearly 10 times when the accuracy is reduced by less than 1%.
Chip-level deployment and implementation
For smart driving applications, TI’s TDA series chips use a multi-core heterogeneous chip architecture to achieve a balance between computing power and power consumption, and the sub-processors are configurable, such as DSP and EVE and other sub-processor units can be selected , In order to achieve a more suitable cost performance according to system requirements.
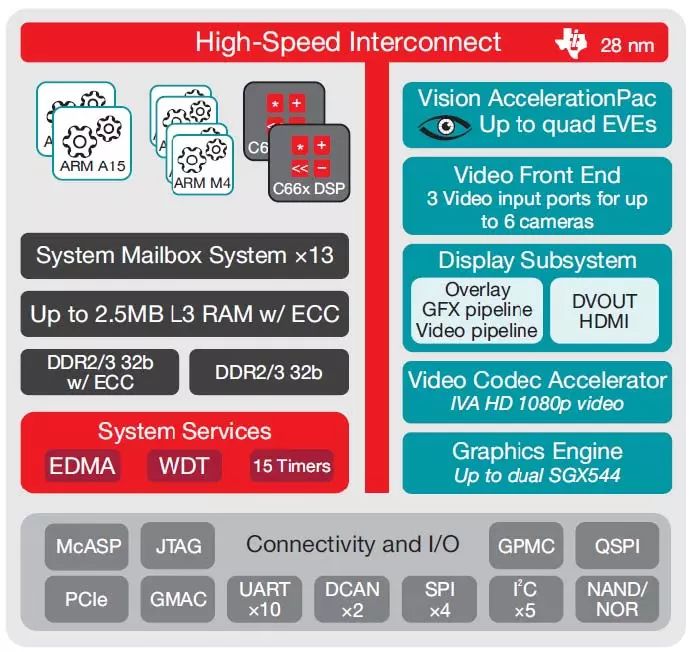
The overall chip architecture is shown in the figure
The biggest advantage of the multi-core heterogeneous architecture is the ability to hetero-core different types of computing or control tasks. In the original design of the TITDA series of chips, the middle and low-level computing tasks of visual perception are mainly concentrated on the two types of sub-processors, DSP and EVE. :
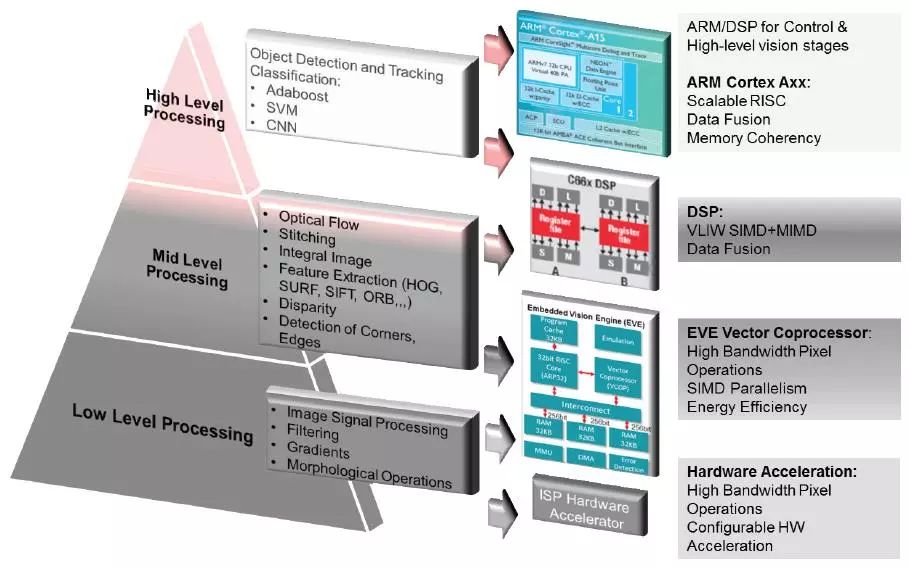
Design of TITDA series chips
As a vector hardware accelerator specially designed by TI for smart driving applications, EVE can achieve an 8 times increase in computing performance compared to other existing smart driving chips under the same power consumption.
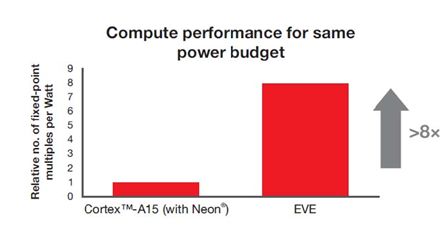
Each EVE core can achieve an 8-fold increase in computing performance
For the most time-consuming convolution operation part of deep neural networks, in the deployment phase, Forward Qichuang mainly uses the EVE core among them for calculation. Using the SIMD feature in EVE, the convolution operation part in FINet can be accelerated About 8 times.
After completing the deployment on TI chips, the forward Qichuang FINet network as a whole can meet the system performance requirements of real-time perception.
On mature ASICs such as TITDA, through the three major steps of network design, network optimization and chip deployment, the preliminary framework of deep neural networks can be basically realized.
In the subsequent productization process, it is necessary to perform a closed loop iteration of these three steps according to the actual system requirements, in order to achieve the best balance between system performance and computing power.
24V Battery Pack ,Large Battery Pack,24 V Battery Pack,24V Lithium Ion Battery Pack
Zhejiang Casnovo Materials Co., Ltd. , https://www.casnovonewenergy.com