Natural language inference data set "artificial traces" are serious, model performance is overestimated
Editor's note: The data sets used in natural language reasoning have been researched and developed in recent years, but in this paper, researchers from universities such as the University of Washington, Carnegie Mellon University, and New York University have found that these data sets are inevitable. Obvious “artificial traces†make the performance of the model overestimated, and the problem of evaluating natural language inference models still exists. The following is the compilation of wisdom.
Natural language reasoning is one of the most widely studied areas in the NLP field. With this technology, many complex semantic tasks such as question answering and text summarization can be solved. Large-scale data sets for natural language reasoning are created by providing a crowd of workers with a sentence (premise) p and then creating three new sentences (hypotheses) associated with them. The purpose of natural language reasoning is to determine whether h can be inferred from the semantics of p. We have shown that with this approach, a large portion of the data can be viewed only by looking at the newly generated sentences, without having to look at the "premise". Specifically, a simple text classification model has a 67% correct rate for sentence classification on the SNLI dataset and 53% accuracy on MultiNLI. Analysis shows that specific linguistic phenomena, such as negation and ambiguity, are very relevant to certain categories of reasoning. So this study shows that the success of the current natural language inference model is overestimated, and this problem is still difficult to solve.
In 2015, Bowman et al. created a large-scale inferred data set SNLI through crowdsourcing tagging; in 2018, Williams et al. introduced the MultiNLI data set. In this process, the researchers extract a certain premise sentence p from some corpora, so that the crowdsourcing caller creates three new sentences based on p. The created sentence has three relationship criteria with p:
Entailment: h is very relevant to p;
Neutral: h may be related to p;
Contradiction: h is absolutely irrelevant to p.
The following are specific examples of the SNLI data set:

In this paper, we find that the artificial artifacts generated by crowdsourcing are too obvious, so that the classifier can correctly classify it without looking at the conditional sentence p. Below we will explain the analysis process in detail.
The "artificial traces" in the notes are actually very obvious.
We suspect that the framework of the annotation task has a significant impact on the crowdsourcing staff when writing the sentence, and this effect is reflected in the data, which we call "annotation artifacts."
To determine the extent to which such human behavior affects the data, we train a model to predict the tags that generate the sentences without having to look at the premise sentences. Specifically, we use the off-the-shelf text classifier fastText, which models text into many words and bigrams to predict the label of a sentence.
The table below shows that most of the data in each test set can be correctly classified without looking at the premise, which also proves that the classifier can perform well even without modeling natural language inference.
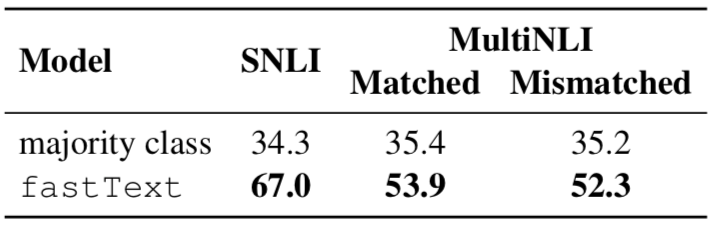
Manual annotation features
As we said before, more than half of MultiNLI data and two-thirds of SNLI data have obvious artifacts. In order to summarize their characteristics, we will analyze the data roughly, focusing on the choice of vocabulary and the length of the sentence. .
Vocabulary selection
To understand whether the choice of a particular vocabulary would affect the classification of a sentence, we calculated the point mutual information (PMI) between each word and category in the training set:
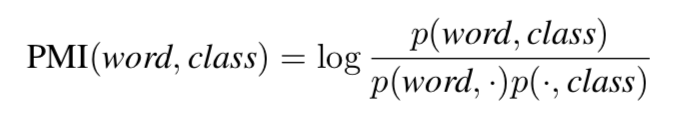
The table below shows the words that are most relevant to the category in each category, and the proportion of those words in the training statement.
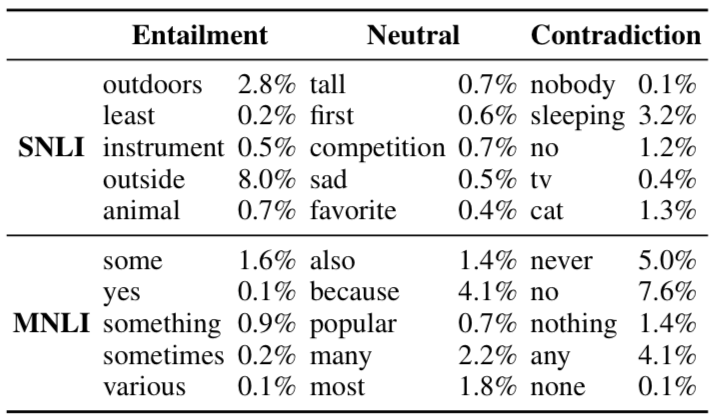
Related sentence (Entailment)
The generated sentences that are fully related to the premise sentences contain common vocabulary, such as animals, musical instruments, and outdoor, and these words may also lead to more specific words such as puppies, guitars, beaches, and the like. In addition, these will replace the approximations (some, at least, various, etc.) with exact numbers, and will remove explicit genders. Some will also have specific environments, such as indoors or outdoors, which are the personality characteristics of the images in the SNLI dataset.
Neutral sentence
Among the sentences of neutral relations, the most common ones are modifiers (high, sad, popular) and top-level words (first, favorite, most). In addition, neutral sentences are more common in reason and purpose clauses, for example.
Irrelevant sentence
Negative words such as "no one", "no", "never", "no", etc. are common words of irrelevant sentences.
Sentence length
We find that the number of tokens in the generated sentence is not evenly distributed among different inference categories. The figure below shows that tokens tend to be longer in neutral sentences, and related sentences tend to be shorter. The difference in sentence length may indicate that the crowdsourcing worker simply deleted a few words from the premise sentence p when generating the relevant sentence. In fact, when each sentence is represented by bag of words, 8.8% of the relevant sentences in SNLI are completely contained in the premise sentence, while only 0.2% of the neutral and contradictory sentences contain the premise.
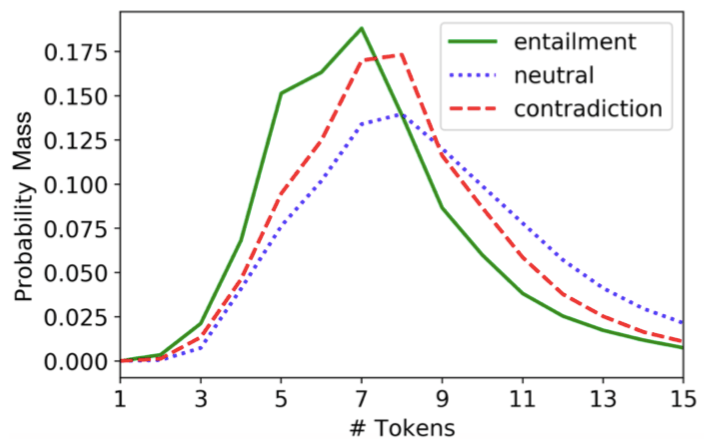
in conclusion
By observing the results and comparing other manual annotation analyses, we have three main conclusions.
Many data sets contain "artificial marks"
The supervision model needs to use manual annotation. Levy et al. demonstrated that the supervised lexical reasoning model has largely generated artificially generated vocabulary in data sets.
Manual annotations overestimate model performance. Most test sets rely on manual annotation to solve problems alone, so we encourage the development of additional standards that give people an idea of ​​the true performance of the NLI model.
Lithium batteries come in all shapes and sizes, but for some commercial energy storage market, such as Solar System, Telecom Tower, UPS system, data center, it can make sense to have a modular 19″ format Lithium Battery. This makes putting battery together and working together on a system much easier. Such a lithium battery is available from UFO POWER.
Telecom networks has become an vital part for the economy, daily communication, etc around the world. Renewable energy such as solar has been a new option of power supply for telecommunication base station. Due to the high reliability of telecommunication base station, highly-reliable and highly-safe batteries are required as the telecommunication power solution. Because of the stable and safe characteristics of Lithium Iron Phosphate Battery, the demand of Lithium Battery for energy storage in telecommunication base station market is increasing.
Traditional lead-acid battery has high requirement of the room environment and maintenance, which makes it less convenience and increases cost for telecommunication base station. However, lithium iron phosphate battery (LiFePO4) has high energy density, which makes compact size design possible when compared to a lead-acid battery with the same capacity. The compact size of LiFePO4 Battery Pack is suitable to meet the requirement of some limited spaces. Besides, the lithium iron phosphate (LiFePO4) battery has a longer cycle life than traditional lead-acid battery which means it could serve for a long time without frequent replacement. It can be a drop-in replacement of lead-acid battery and save a lot of maintenance and replacement cost. With no toxic material in lithium iron phosphate battery, it is a greener battery in accordance with the appeal for sustainable world.
> Safe and stable Lithium Iron Phosphate Battery (LiFePO4/LFP)
It can be a reliable backup power for base station.
> Smart BMS for battery protection
It provides over charge and discharge protection, over current protection, short circuit and over voltage protection, etc.
> Optional GPRS Module to provide theft prevention solution.
> Optional LCD Display to monitor battery status.
> Strong scalability
Making connections in parallel possible for more capacity of the equipment.
Application

LFP Battery Advantage
Allows offering more energy storage capacity in less space.
> Reliable Backup Power
With built-in BMS (Battery Management System), making the management of the models effectively and safely.
Quality Certifications
ISO, UL, CE, RoHS, UN38.3, TUV, IEC, and so on.
Quality Control
> First Product Inspection
> In-process Inspection
> Pre-shipment Inspection
> Container loading Inspection
Telecom Battery,Telecom Tower Data Center,Telecom Battery Rack,Telecom Battery System
ShenZhen UFO Power Technology Co., Ltd. , https://www.ufobattery.com