Dry goods: Deep analysis of the latest speech recognition system and framework of HKUST
According to Lei Feng, the author of this article is Wei Si, Ph.D., vice president of the Research Institute of Science and Technology of HKUST. His major research areas include speech signal processing, pattern recognition, and artificial intelligence. He also has a number of industry-leading scientific research achievements. Zhang Shiliang, Pan Jia, Zhang Zhijiang Research fellow, Institute of Science and Technology, Beijing. Liu Cong, Wang Zhiguo, Vice President, Science and Technology Institute of Science and Technology. Responsibility: Zhou Jianding.
As the most natural and convenient communication method, voice has always been one of the most important research areas for human-machine communication and interaction. Automatic Speech Recognition (ASR) is a key technology for realizing human-computer interaction. The problem to be solved is to let the computer "understand" human speech and transfer the speech into text. After several decades of development, automatic speech recognition technology has achieved remarkable results. In recent years, more and more speech recognition intelligent software and applications have gone into people's daily lives. Apple's Siri, Microsoft's Xiao Na, Science and Technology's voice input method and Consonance are all typical examples. This article will introduce the development of speech recognition and the latest technological progress from the perspective of HKUST.
We first briefly review the development history of speech recognition, and then introduce the current mainstream speech recognition system based on deep neural networks. Finally, we will focus on the latest developments in the speech recognition system of HKUST.
Speech Recognition Critical Breakthrough ReviewThe study of speech recognition originated in the 1950s. The main researcher at that time was Bell Labs. The early speech recognition system was a simple isolated word recognition system. For example, in 1952 Bell Labs implemented ten English word recognition systems. Since the 1960s, CMU's Reddy has begun pioneering work on continuous speech recognition. However, the technology for speech recognition during this period has progressed so slowly that John Pierce of Bell Laboratories in 1969 compared speech recognition in an open letter to “convert water to gasoline, extract gold from the sea, and treat cancer. "It's almost impossible to achieve things. In the 1970s, the dramatic increase in computer performance and the development of basic research in pattern recognition, such as the emergence of codebook generation algorithms (LBG) and linear predictive coding (LPC), facilitated the development of speech recognition.
During this period, the US Department of Defense Advanced Research Projects Agency (DARPA) intervened in the field of speech and established a speech understanding research program. The research program includes many top research institutions such as BBN, CMU, SRI, and IBM. IBM and Bell Labs have launched a real-time PC-side isolated word recognition system. The 1980s was the period of rapid development of speech recognition. Two of the key technologies were the improvement of the theory and application of hidden Markov models (HMM) and the application of the NGram language model.
At this point, speech recognition began to evolve from isolated word recognition systems to large vocabulary continuous speech recognition systems. For example, the SPHINX system developed by Kai-Fu Lee is the first “non-specific person continuous speech recognition system†developed based on statistical principles. The core framework is to use the Hidden Markov Model to model the timing of speech, and Gaussian Mixture Model (GMM) to model the observed probability of speech. The speech recognition framework based on GMM-HMM has been the dominant framework of speech recognition systems for a long time to come. In the 90s of last century, speech recognition was basically mature. The main progress was the introduction of discriminative training criteria and model adaptation methods for acoustic models of speech recognition. The HTK toolkit launched by the Cambridge Speech Recognition Group during this period has played a significant role in promoting the development of speech recognition. Since then, the development of speech recognition has been slow, and the mainstream framework GMM-HMM has stabilized, but the recognition effect is still far from practical, and the research of speech recognition has become a bottleneck.
The key breakthrough started in 2006. This year, Hinton proposed a deep belief network (DBN), prompting the recovery of deep neural network (DNN) research and setting off an upsurge of deep learning. In 2009, Hinton and his student D. Mohamed applied deep neural networks to the acoustic modeling of speech and succeeded in the small vocabulary continuous speech recognition database TIMIT. In 2011, Microsoft Research Institutes Yu Dong and Deng Li published deep neural network application articles on speech recognition and achieved breakthroughs in large vocabulary continuous speech recognition tasks. Since the speech recognition framework based on GMM-HMM has been broken, many researchers have turned to the research of speech recognition systems based on DNN-HMM.
Speech Recognition System Based on Deep Neural NetworkThe speech recognition system based on deep neural network mainly adopts the framework shown in Figure 1. Compared with the traditional speech recognition system based on GMM-HMM, the biggest change is to use deep neural network to replace the GMM model to model the observed probability of speech. The original mainstream deep neural network is the simplest feedforward deep neural network (FDNN). The advantages of DNN over GMM are: 1. The use of DNN to estimate the posterior probability distribution of HMM states does not require assumptions about the distribution of speech data; 2. The input features of DNN can be a combination of multiple features, including discrete or continuous; 3. The DNN can use the structural information contained in adjacent speech frames.
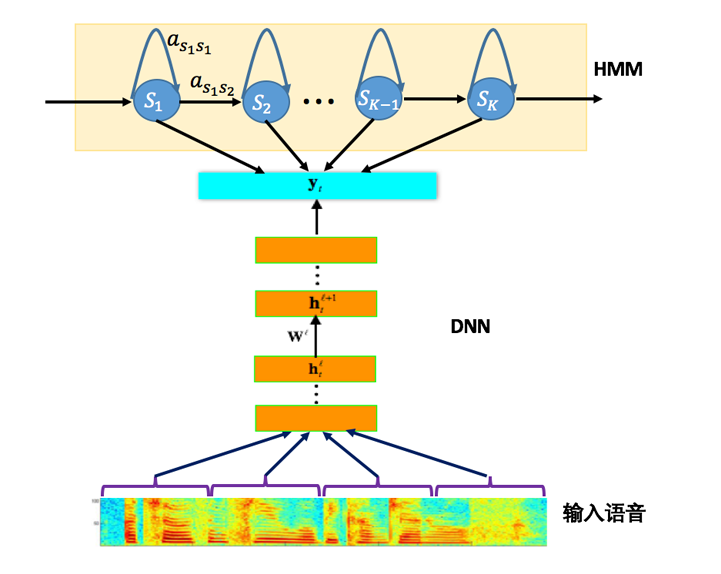
Fig. 1 Speech recognition system framework based on deep neural network
Speech recognition needs to preprocess the waveforms such as windowing, frame division, and feature extraction. When training GMM, the input features can only be a single frame signal, but for DNN can use splice frames as input, these are the key factors that DNN can get a great performance improvement compared to GMM. However, speech is a complex and time-varying signal with strong correlation between frames. This correlation is mainly reflected in the phenomenon of co-pronunciation in speech, often with several words before and after the word that we are about to say. The effect, that is, the long-term correlation between frames of speech. A certain degree of contextual information can be learned by using splicing frames. However, since the window length of the DNN input is fixed, the mapping relationship from the fixed input to the input is learned, resulting in the DNN's weaker modeling of the long-term correlation of the timing information.

Figure 2 Schematic diagram of DNN and RNN
Taking into account the long-term correlation of speech signals, a natural idea is to use a neural network model with stronger long-term modeling capabilities. Thus, the Recurrent Neural Network (RNN) has gradually replaced the traditional DNN as the mainstream speech recognition modeling solution in recent years. As shown in Fig. 2, compared with the feedforward neural network DNN, the NN adds a feedback connection to the hidden layer. That is to say, part of the input of the RNN hidden layer at the current moment is the hidden layer output of the previous moment, which makes The RNN can see the information of all previous moments through the loop feedback connection, which gives the RNN memory function. These features make RNN very suitable for modeling timing signals. The introduction of the Long-Short Term Memory (LSTM) solves the problem of the disappearance of traditional simple RNN gradients, making the RNN framework practical in the field of speech recognition and gaining the effect of surpassing DNN. It has been used in the industry at present. More advanced voice system. In addition, the researchers also made further improvement work on the basis of RNN. Figure 3 is the main RNN acoustic model framework in current speech recognition. It mainly consists of two parts: deep two-way RNN and serial short-term classification (Connectionist Temporal Classification, CTC) output layer. When the bi-directional RNN judges the current speech frame, not only the historical speech information but also the future speech information can be used to make more accurate decisions; the CTC enables the training process to eliminate the need for frame-level annotation and achieve an effective "end-to-end" End "training.
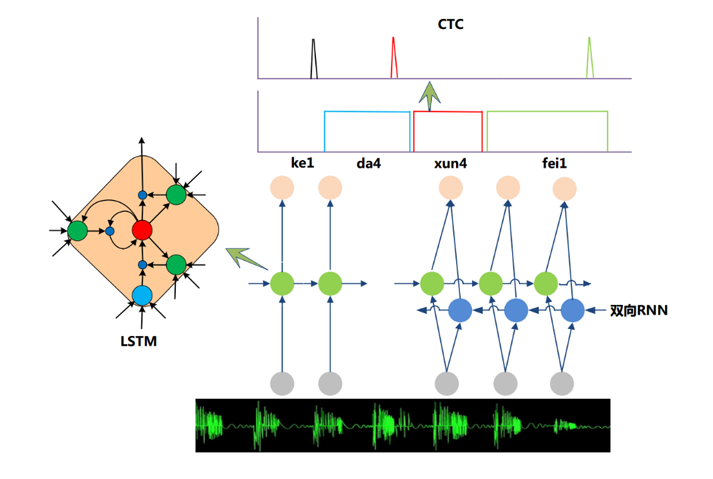
Figure 3 Mainstream speech recognition system framework based on RNN-CTC
HKUST’s latest speech recognition system
Many international or domestic academic or industrial institutions have mastered the RNN model and conducted research at one or more of the above technical points. However, the above technical points can generally obtain better results when they are studied separately, but if you want to merge these technical points together, you will encounter some problems. For example, the combined improvement of multiple technologies will be smaller than the increase of each technical point. For another example, for the current mainstream two-way RNN speech recognition system, one of the biggest problems in the practical application of the speech recognition system is that only a complete speech segment can theoretically be used to successfully utilize future information. This makes it very time-consuming and can only be used to handle some offline tasks. For real-time speech interactions, such as speech input methods, bidirectional RNNs are obviously not applicable. Furthermore, the RNN has a strong fit to contextual correlation and is more likely to fall into overfitting than DNN. It is easy to introduce additional abnormality recognition errors due to local non-robustness of the training data. Finally, because RNN has a more complex structure than DNN, it brings greater challenges to the training of RNN models under massive data.
News Flight FSMN Speech Recognition Framework
In view of the above problems, HKUST developed a new framework called the Feed-forward Sequential Memory Network (FSMN). This framework can integrate the above points well, and at the same time, each technical point can be superimposed on the improvement of the effect. It is worth mentioning that FSMN adopts a non-cyclic feed-forward structure and only needs 180ms delay, which achieves the same effect as bidirectional RNN.
Figure 4(a) shows the structure of the FSMN. Compared to the traditional DNN, we added a module called "memory block" next to the hidden layer to store useful historical information and future information for judging the current speech frame. . Fig. 4(b) shows the timing structure of the memory information of one frame of memory in left and right memories of the two-way FSMN (in actual tasks, the required history of memory and the length of future information can be adjusted according to the task requirements). From the figure we can see that, unlike the traditional RNN based on cyclic feedback, the memory function of the FSMN memory block is implemented using a feedforward structure. This feedforward structure has two major benefits:
First of all, when the bidirectional FSMN memorizes future information, there is no restriction that the traditional bidirectional RNN must wait for the end of speech input to judge the current speech frame. It only needs to wait for a finite-length future speech frame. As we mentioned earlier, we The bi-directional FSMN can achieve the same effect as the bi-directional RNN when the delay is controlled at 180ms;
Secondly, as mentioned earlier, the traditional simple RNN is because the gradients in the training process are propagated forward one by one in time, so the exponentially decaying gradient disappears. This results in the RNN theoretically having infinitely long memory. The inhabited information is very limited. However, in the memory network based on the feedforward timing expansion structure of the FSMN, gradients are transmitted back to the moments in the connection process according to the connection weights of the memory block and the hidden layer in FIG. 4 during the training process. These connection weights can be obtained. Determine the impact of input at different times on judging the current speech frame, and the decay of this gradient propagation at any moment is constant, and it is also trainable, so FSMN solves the gradient disappearance in RNN in a simpler way. The problem is that it has LSTM-like long-term memory capabilities.
In addition, in terms of model training efficiency and stability, since FSMN is based entirely on feed-forward neural networks, there is no case in which the length of a sentence in a mini-batch needs to be filled with zeros to cause wasted computations in a RNN training, and the feedforward structure also makes Its higher degree of parallelism can maximize the use of GPU computing power. From the weighted coefficient distribution at each moment in the two-way FSMN model memory block converged by the final training, we observe that the weight value is basically the maximum at the current moment, and gradually decreases toward the left and right sides. This is also in line with expectation. Further, FSMN can be combined with CTC criteria to achieve "end-to-end" modeling in speech recognition.
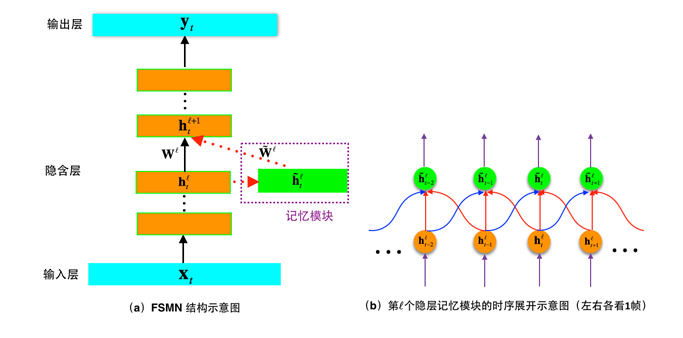
Figure 4 FSMN block diagram
HKUST's DFCNN speech recognition framework
The success of FSMN gives us a good inspiration: the long-term correlation of speech does not need to observe the entire sentence, nor does it need to use a recursive structure, as long as the speech context information is long enough to be well expressed. There is enough help for the decision of the current frame, and Convolutional Neural Networks (CNN) can do the same. Â
CNN was used in speech recognition systems as early as 2012, and many researchers have been actively involved in the research of CNN-based speech recognition systems, but there has been no major breakthrough. The main reason is that they did not break through the traditional feed-forward neural network using fixed-length frame splicing as the input mental ideology, and could not see long enough speech context information. Another drawback is that they only regard CNN as a feature extractor. Therefore, the number of convolution layers used is very small, generally only one or two layers. Such a convolutional network has very limited expressive power. In response to these problems, combined with the experience in the development of FSMN, we developed a speech recognition framework called Deep Fully Convolutional Neural Network (DFCNN), which uses a large number of convolutional layers to directly address the entire sentence speech. The signal is modeled to better express the long-term correlation of the speech.
The structure of the DFCNN is shown in Fig. 5. It directly converts a sentence of speech into an image as an input. That is, Fourier transform is performed on each frame of speech first, then time and frequency are used as two dimensions of the image, and then very many The combination of a convolutional layer and a pooling layer models the entire sentence speech, and the output unit directly corresponds to the final recognition result such as a syllable or a Chinese character. The working mechanism of DFCNN is like a highly respected phonetics expert. By “watching†the phonogram, the content expressed in the voice can be known. For many readers, at first glance it may be thought that science fiction is being written, but after reading our analysis below, I believe everyone will feel that this structure is so natural.
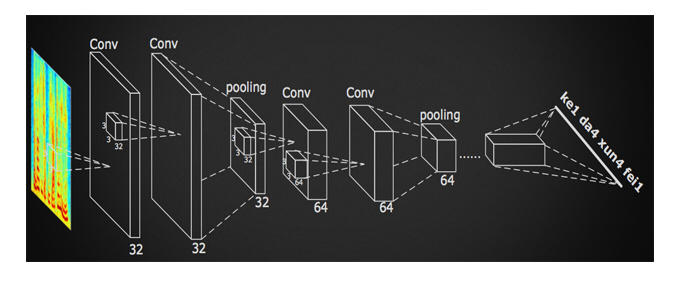
Figure 5 DFCNN schematic
First of all, from the input side, traditional speech features use various artificially designed filter banks to extract features after the Fourier transform, resulting in loss of information in the frequency domain, and the loss of information in the high frequency region is particularly evident. Traditional speech features must use very large frame shifts for computational considerations, which undoubtedly causes information loss in the time domain and is more pronounced when the speaker speaks faster. Therefore, DFCNN directly uses the spectral map as input, which has a natural advantage over other speech recognition frameworks that use traditional speech features as input. Secondly, from the point of view of the model structure, DCNNN is different from CNN in traditional speech recognition. It draws on the best network configuration in image recognition, using 3x3 small convolution kernels in each convolution layer and in multiple volumes. The pooling layer followed by the pooling layer greatly enhances CNN's expressiveness. At the same time, by accumulating a large number of such convolutional pooling layers, DFCNN can see very long history and future information. It ensures that the DFCNN can well express the long-term correlation of speech, and is more robust than the RNN network structure. Finally, from the output point of view, DFCNN can also be combined with the recently hot CTC program to achieve the end-to-end training of the entire model, and its special structure including the pooling layer can make the above end-to-end training become more stable.
Combining with several other technical points, HKUST's DFCNN speech recognition framework has thousands of hours of internal Chinese speech message dictation tasks, which is 15% higher than the current industry's best speech recognition framework bi-directional RNN-CTC system. The performance of the upgrade, combined with the intersection of the intersection of science and technology and the intersection of fly and HPC platform and multi-GPU concurrent acceleration technology, training speed is superior to the traditional two-way RNN-CTC system too. DFCNN's proposal opens up a new world of speech recognition. Based on the DFCNN framework, we will also carry out more related research work. For example, both bidirectional RNN and DFCNN can provide long-term history and future information, but both Whether there is complementarity between expressions is a question worth considering.
Deep learning platformAll the above researches conducted by the University of Science and Technology are very effective in speech recognition. At the same time, HKUST is also aware that these deep neural networks require a large amount of data and calculations to train. For example, 20,000 hours of voice data is about 12,000 PFlop calculations. If you train on an E5-2697 v4 CPU, it takes about 116 days, which is unacceptable for speech recognition technology research. To this end, the computational characteristics of HKUST’s flight analysis algorithms have created a set of deep learning and computing platforms—deep learning platforms.
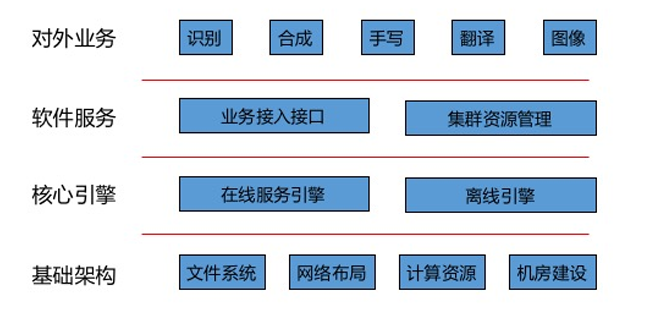
Figure 6 Deep Learning Platform Architecture
As shown in Figure 6, the entire platform is divided into four components. First, the underlying infrastructure selects suitable file systems, network connections, and computing resources based on the amount of voice data, bandwidth accessed, frequency of access, computation, and computing characteristics. Among them, the file system uses a parallel distributed file system, the network uses 10 Gigabit connections, the computing resources use GPU clusters, and a dedicated computer room is built separately. On this basis, the core computing engine is developed for various model training and calculations, such as an engine suitable for CNN calculation, a calculation engine suitable for DNN, and a calculation engine suitable for FSMN/DFCNN. The entire computing engine and infrastructure are still relatively abstract to the users. In order to simplify the use threshold, HKUST has developed the platform's resource scheduling service and the engine's calling service; these efforts have greatly reduced the difficulty of using the cluster resources of the research personnel. Improve research progress. Based on these three basic tasks, HKUST's deep learning platform can support research-related work such as speech recognition, speech synthesis, and handwriting recognition...
HKUST has used GPUs as its main computing component, and combined with the features of the algorithms, it has conducted a large number of GPU parallelization tasks. For example, HKUST designed a parallel computing framework that integrates the elastic-average stochastic gradient descent (EASGD) algorithm on the basis of block model updating (BMUF), and achieved near-linear acceleration on 64 GPUs, greatly improving training efficiency and speeding up Deep-learning related application research process.
Write lastAfter reviewing the history of the development of speech recognition and the latest developments in the HKUST's speech recognition system, we can see that technological breakthroughs are always difficult and slow, and it is important to persist and think constantly. Although the rise of deep neural networks in recent years has greatly improved the performance of speech recognition, we cannot superstitiously believe in existing technologies. Sometime new technologies will replace existing technologies, and HKUST hopes to Continuous breakthrough in speech recognition technology through continuous technological innovation.
Lei Feng Net Note: This article is authorized by the CSDN authorized Lei Feng network (search "Lei Feng network" public number attention) reproduced, if you need to reprint please contact the original author.
Integrated Electromagnetic Flowmeter
Integrated Electromagnetic Flowmeter means the flowmeter sensor and converter are integrated in the site and all data can be read directly.
The shortcoming is can not be protected well and converter easily damaged. So when installing, user must consider the site condition, and try to aviod heavy moisture or possibly be hit, so that the life and accuracy may be guaranteed.
Integrated Electromagnetic Flow Meter,Integrated Flow Meter,Fire Fighting Flowmeter,Carbon Steel Fire Fighting Flowmeter
Kaifeng Chuangxin Measurement & Control Instrument Co., Ltd. , https://www.kfcxflowmeter.com